MC-Dropout#
[1]:
%%capture
%pip install git+https://github.com/lightning-uq-box/lightning-uq-box.git
Theoretic Foundation#
MC-Dropout is an approximate Bayesian method with sampling. A fixed dropout rate \(p \in [0,1)\) is used, meaning that random weights are set to zero during each forward pass with the probability \(p\). This models the network weights and biases as a Bernoulli distribution with dropout probability \(p\). While commonly used as a regularization method, Gal, 2016 showed that activating dropout during inference over multiple forward passes yields an approximation to the posterior over the network weights. Due to its simplicity it is widely adopted in practical applications, but MC-Dropout and variants thereof have also been criticized for their theoretical shortcomings Hron, 2017 and Osband, 2016.
For the MC Dropout model the prediction consists of a predictive mean and a predictive uncertainty. For the predictive mean, the mean is taken over \(m \in \mathbb{N}\) forward passes through the network \(f_{p,\theta}\) with a fixed dropout rate \(p\), resulting in different weights \(\{\theta_i\}_{i=1}^m\), given by
The predictive uncertainty is given by the standard deviation of the predictions over \(m\) forward passes,
Note that in Kendall, 2017 the approach is extended to include aleatoric uncertainty. We also consider combining this method with the previous model Gaussian network, as in Kendall, 2017, aiming at disentangling the data and model uncertainties, abbreviated as MC Dropout GMM. For the MC Dropout GMM model, the prediction again consists of a predictive mean and a predictive uncertainty \(f_{p,\theta}(x^{\star}) = (\mu_{p,\theta}(x^{\star}), \sigma_{p,\theta}(x^{\star}))\). Here the predictive mean is given by the mean taken over \(m\) forward passes through the Gaussian network mean predictions \(\mu_{p,\theta}\) with a fixed dropout rate \(p\), resulting in different weights \(\{\theta_i\}_{i=1}^m\), given by
The predictive uncertainty is given by the standard deviation of the Gaussian mixture model obtained by the predictions over \(m\) forward passes,
Imports#
[2]:
import os
import tempfile
from functools import partial
import matplotlib.pyplot as plt
import torch.nn as nn
from lightning import Trainer
from lightning.pytorch import seed_everything
from lightning.pytorch.loggers import CSVLogger
from torch.optim import Adam
from lightning_uq_box.datamodules import ToyHeteroscedasticDatamodule
from lightning_uq_box.models import MLP
from lightning_uq_box.uq_methods import NLL, MCDropoutRegression
from lightning_uq_box.viz_utils import (
plot_calibration_uq_toolbox,
plot_predictions_regression,
plot_toy_regression_data,
plot_training_metrics,
)
plt.rcParams["figure.figsize"] = [14, 5]
[3]:
seed_everything(0) # seed everything for reproducibility
Seed set to 0
[3]:
0
We define a temporary directory to look at some training metrics and results.
[4]:
my_temp_dir = tempfile.mkdtemp()
Datamodule#
To demonstrate the method, we will make use of a Toy Regression Example that is defined as a Lightning Datamodule. While this might seem like overkill for a small toy problem, we think it is more helpful how the individual pieces of the library fit together so you can train models on more complex tasks.
[5]:
dm = ToyHeteroscedasticDatamodule()
X_train, Y_train, train_loader, X_test, Y_test, test_loader, X_gtext, Y_gtext = (
dm.X_train,
dm.Y_train,
dm.train_dataloader(),
dm.X_test,
dm.Y_test,
dm.test_dataloader(),
dm.X_gtext,
dm.Y_gtext,
)
[6]:
fig = plot_toy_regression_data(X_train, Y_train, X_test, Y_test)
Model#
For our Toy Regression problem, we will use a simple Multi-layer Perceptron (MLP) that you can configure to your needs. For the documentation of the MLP see here.
[7]:
network = MLP(
n_inputs=1,
n_hidden=[50, 50, 50],
n_outputs=2,
dropout_p=0.1,
activation_fn=nn.Tanh(),
)
network
[7]:
MLP(
(model): Sequential(
(0): Linear(in_features=1, out_features=50, bias=True)
(1): Tanh()
(2): Dropout(p=0.1, inplace=False)
(3): Linear(in_features=50, out_features=50, bias=True)
(4): Tanh()
(5): Dropout(p=0.1, inplace=False)
(6): Linear(in_features=50, out_features=50, bias=True)
(7): Tanh()
(8): Dropout(p=0.1, inplace=False)
(9): Linear(in_features=50, out_features=2, bias=True)
)
)
With an underlying neural network, we can now use our desired UQ-Method as a sort of wrapper. All UQ-Methods are implemented as LightningModule that allow us to concisely organize the code and remove as much boilerplate code as possible.
[8]:
mc_dropout_module = MCDropoutRegression(
model=network,
optimizer=partial(Adam, lr=1e-2),
loss_fn=NLL(),
num_mc_samples=25,
burnin_epochs=50,
)
Trainer#
Now that we have a LightningDataModule and a UQ-Method as a LightningModule, we can conduct training with a Lightning Trainer. It has tons of options to make your life easier, so we encourage you to check the documentation.
[9]:
logger = CSVLogger(my_temp_dir)
trainer = Trainer(
accelerator="cpu",
max_epochs=300, # number of epochs we want to train
logger=logger, # log training metrics for later evaluation
log_every_n_steps=1,
enable_checkpointing=False,
enable_progress_bar=False,
default_root_dir=my_temp_dir,
)
GPU available: False, used: False
TPU available: False, using: 0 TPU cores
💡 Tip: For seamless cloud logging and experiment tracking, try installing [litlogger](https://pypi.org/project/litlogger/) to enable LitLogger, which logs metrics and artifacts automatically to the Lightning Experiments platform.
Training our model is now easy:
[10]:
trainer.fit(mc_dropout_module, dm)
| Name | Type | Params | Mode | FLOPs
-------------------------------------------------------------------
0 | model | MLP | 5.3 K | train | 0
1 | loss_fn | NLL | 0 | train | 0
2 | train_metrics | MetricCollection | 0 | train | 0
3 | val_metrics | MetricCollection | 0 | train | 0
4 | test_metrics | MetricCollection | 0 | train | 0
-------------------------------------------------------------------
5.3 K Trainable params
0 Non-trainable params
5.3 K Total params
0.021 Total estimated model params size (MB)
23 Modules in train mode
0 Modules in eval mode
0 Total Flops
/home/docs/checkouts/readthedocs.org/user_builds/lightning-uq-box/envs/latest/lib/python3.12/site-packages/lightning/pytorch/utilities/_pytree.py:21: `isinstance(treespec, LeafSpec)` is deprecated, use `isinstance(treespec, TreeSpec) and treespec.is_leaf()` instead.
`Trainer.fit` stopped: `max_epochs=300` reached.
Training Metrics#
To get some insights into how the training went, we can use the utility function to plot the training loss and RMSE metric.
[11]:
fig = plot_training_metrics(
os.path.join(my_temp_dir, "lightning_logs"), ["train_loss", "trainRMSE"]
)

Prediction#
For prediction we can either rely on the trainer.test() method or manually conduct a predict_step(). Using the trainer will save the predictions and some metrics to a CSV file, while the manual predict_step() with a single input tensor will generate a dictionary that holds the mean prediction as well as some other quantities of interest, for example the predicted standard deviation or quantile.
[12]:
# save predictions
trainer.test(mc_dropout_module, dm.test_dataloader())
────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────
Test metric DataLoader 0
────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────
testMAE 0.29997870326042175
testR2 0.7841544151306152
testRMSE 0.46558526158332825
────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────
[12]:
[{'testMAE': 0.29997870326042175,
'testR2': 0.7841544151306152,
'testRMSE': 0.46558526158332825}]
Evaluate Predictions#
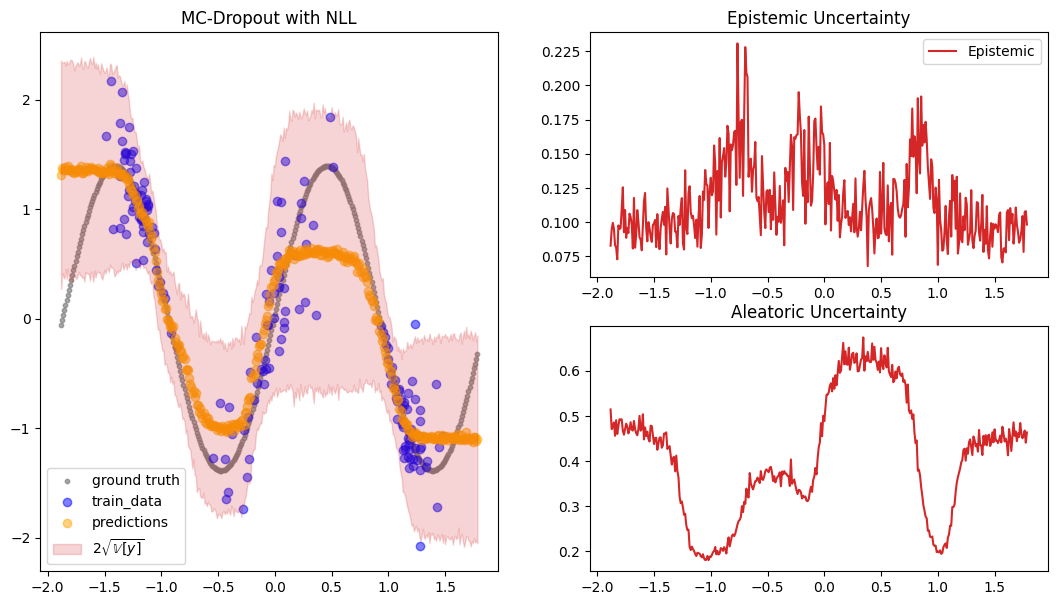
The constructed Data Module contains two possible test variable. X_test are IID samples from the same noise distribution as the training data, while X_gtext (“X ground truth extended”) are dense inputs from the underlying “ground truth” function without any noise that also extends the input range to either side, so we can visualize the method’s UQ tendencies when extrapolating beyond the training data range. Thus, we will use X_gtext for visualization purposes, but use X_test to
compute uncertainty and calibration metrics because we want to analyse how well the method has learned the noisy data distribution.
[13]:
preds = mc_dropout_module.predict_step(X_gtext.to(mc_dropout_module.device))
fig = plot_predictions_regression(
X_train,
Y_train,
X_gtext,
Y_gtext,
preds["pred"],
preds["pred_uct"],
epistemic=preds["epistemic_uct"],
aleatoric=preds["aleatoric_uct"],
title="MC-Dropout with NLL",
)
For some additional metrics relevant to UQ, we can use the great uncertainty-toolbox that gives us some insight into the calibration of our prediction. For a discussion of why this is important, see …
[14]:
preds = mc_dropout_module.predict_step(X_test.to(mc_dropout_module.device))
fig = plot_calibration_uq_toolbox(
preds["pred"].cpu().numpy(),
preds["pred_uct"].cpu().numpy(),
Y_test.cpu().numpy(),
X_test.cpu().numpy(),
)
