Conformalized Quantile Regression#
[1]:
%%capture
%pip install git+https://github.com/lightning-uq-box/lightning-uq-box.git
Theoretic Foundation#
Conformalized Quantile Regression (CQR) is a post-hoc uncertainty quantification method to yield calibrated predictive uncertainty bands with proven coverage guarantees Angelopoulos, 2021. Based on a held out calibration set, CQR uses a score function to find a desired coverage quantile \(\hat{q}\) and conformalizes the QR output by adjusting the quantile bands via \(\hat{q}\) for an unseen test point as follows \(x_{\star}\):
where \(\hat{y}_{\alpha/2}(x_{\star})\) is the lower quantile output and \(\hat{y}_{1-\alpha/2}(x_{\star})\), Romano, 2019.
NOTE: In the current setup we follow the Conformal Prediction Tutorial linked below, where they apply Conformal Prediction to Quantile Regression. However, Conformal Prediction is a more general statistical framework and model-agnostic in the sense that whatever Frequentist or Bayesian approach one might take, Conformal Prediction can be applied to calibrate your predictive uncertainty bands.
Conformalize the quantile regression model. From Chapter 2.2 of Angelopoulos, 2021.
Identify a heuristic notion of uncertainty for our problem and use it to construct a scoring function, where large scores imply a worse fit between inputs \(X\) and scalar output \(y\). In the regression case, it is recommended to use a quantile loss that is then adjusted for prediction time via the conformal prediction method.
Compute the Score function output for all data points in your held out validation set and compute a desired quantile \(\hat{q}\) across those scores.
Conformalize your quantile regression bands with the computed \(\hat{q}\). The prediction set for an unseen test point \(x_{\star}\) is now \(T(x_{\star})=[\hat{y}_{\alpha/2}(x_{\star})-\hat{q}, \hat{y}_{1-\alpha/2}(x_{\star})+\hat{q}]\) where \(\hat{y}_{\alpha/2}(x_{\star})\) is the lower quantile model output and \(\hat{y}_{1-\alpha/2}(x_{\star})\) is the upper quantile model output. This means we are adjusting the quantile bands symmetrically on either side and this conformalized prediction interval is guaranteed to satisfy our desired coverage requirement regardless of model choice.
The central assumption conformal prediction makes is exchangeability, which restricts us in the following two ways Barber, 2022: 1. The order of samples does not change the joint probability distribution. This is a more general notion to the commonly known i.i.d assumption, meaning that we assume that our data is independently drawn from the same distribution and does not change between the different data splits. In other words, we assume that any permutation of the dataset observations has equal probability. 2. Our modeling procedure is assumed to handle our individual data samples symmetrically to ensure exchangeability beyond observed data. For example a sequence model that weighs more recent samples higher than older samples would violate this assumption, while a classical image classification model that is fixed to simply yield a prediction class for any input image does not. Exchangeability means that if I have all residuals of training and test data, I cannot say from looking at the residuals alone whether a residual belongs to a training or test point. A test point is equally likely to be any of the computed residuals.
Imports#
[2]:
import os
import tempfile
from functools import partial
import matplotlib.pyplot as plt
import numpy as np
import torch
import torch.nn as nn
from lightning import Trainer
from lightning.pytorch import seed_everything
from lightning.pytorch.loggers import CSVLogger
from lightning_uq_box.datamodules import ToyHeteroscedasticDatamodule
from lightning_uq_box.models import MLP
from lightning_uq_box.uq_methods import ConformalQR, QuantileRegression
from lightning_uq_box.viz_utils import (
plot_calibration_uq_toolbox,
plot_predictions_regression,
plot_toy_regression_data,
plot_training_metrics,
)
plt.rcParams["figure.figsize"] = [14, 5]
INFO:root:Asdfghjkl backend not available since the old asdfghjkl dependency is not installed. If you want to use it, run: pip install git+https://git@github.com/wiseodd/asdl@asdfghjkl
[3]:
seed_everything(0) # seed everything for reproducibility
Seed set to 0
[3]:
0
We define a temporary directory to look at some training metrics and results.
[4]:
my_temp_dir = tempfile.mkdtemp()
Datamodule#
To demonstrate the method, we will make use of a Toy Regression Example that is defined as a Lightning Datamodule. While this might seem like overkill for a small toy problem, we think it is more helpful how the individual pieces of the library fit together so you can train models on more complex tasks.
[5]:
dm = ToyHeteroscedasticDatamodule(n_points=1000, calib_fraction=0.6)
(
X_train,
Y_train,
train_loader,
X_test,
Y_test,
test_loader,
X_calib,
Y_calib,
X_gtext,
Y_gtext,
) = (
dm.X_train,
dm.Y_train,
dm.train_dataloader(),
dm.X_test,
dm.Y_test,
dm.test_dataloader(),
dm.X_calib,
dm.Y_calib,
dm.X_gtext,
dm.Y_gtext,
)
[6]:
fig = plot_toy_regression_data(X_train, Y_train, X_test, Y_test)

Model#
For our Toy Regression problem, we will use a simple Multi-layer Perceptron (MLP) that you can configure to your needs. For the documentation of the MLP see here.
[7]:
quantiles = [0.1, 0.5, 0.9]
network = MLP(
n_inputs=1, n_hidden=[50, 50, 50], n_outputs=len(quantiles), activation_fn=nn.Tanh()
)
network
[7]:
MLP(
(model): Sequential(
(0): Linear(in_features=1, out_features=50, bias=True)
(1): Tanh()
(2): Dropout(p=0.0, inplace=False)
(3): Linear(in_features=50, out_features=50, bias=True)
(4): Tanh()
(5): Dropout(p=0.0, inplace=False)
(6): Linear(in_features=50, out_features=50, bias=True)
(7): Tanh()
(8): Dropout(p=0.0, inplace=False)
(9): Linear(in_features=50, out_features=3, bias=True)
)
)
With an underlying neural network, we can now use our desired UQ-Method as a sort of wrapper. All UQ-Methods are implemented as LightningModule, so in this case we will use the Quantile Regression Model.
[8]:
qr_model = QuantileRegression(
model=network, optimizer=partial(torch.optim.Adam, lr=4e-3), quantiles=quantiles
)
Trainer#
Now that we have a LightningDataModule and a UQ-Method as a LightningModule, we can conduct training with a Lightning Trainer. It has tons of options to make your life easier, so we encourage you to check the documentation.
[9]:
logger = CSVLogger(my_temp_dir)
trainer = Trainer(
max_epochs=150, # number of epochs we want to train
logger=logger, # log training metrics for later evaluation
log_every_n_steps=1,
enable_checkpointing=False,
enable_progress_bar=False,
default_root_dir=my_temp_dir,
)
GPU available: False, used: False
TPU available: False, using: 0 TPU cores
HPU available: False, using: 0 HPUs
Training our model is now easy:
[10]:
trainer.fit(qr_model, dm)
| Name | Type | Params | Mode
-----------------------------------------------------------
0 | model | MLP | 5.4 K | train
1 | loss_fn | PinballLoss | 0 | train
2 | train_metrics | MetricCollection | 0 | train
3 | val_metrics | MetricCollection | 0 | train
4 | test_metrics | MetricCollection | 0 | train
-----------------------------------------------------------
5.4 K Trainable params
0 Non-trainable params
5.4 K Total params
0.021 Total estimated model params size (MB)
23 Modules in train mode
0 Modules in eval mode
`Trainer.fit` stopped: `max_epochs=150` reached.
Training Metrics#
To get some insights into how the training went, we can use the utility function to plot the training loss and RMSE metric.
[11]:
fig = plot_training_metrics(
os.path.join(my_temp_dir, "lightning_logs"), ["train_loss", "trainRMSE"]
)

Predictions without the Conformal Procedure#
The constructed Data Module contains two possible test variable. X_test are IID samples from the same noise distribution as the training data, while X_gtext (“X ground truth extended”) are dense inputs from the underlying “ground truth” function without any noise that also extends the input range to either side, so we can visualize the method’s UQ tendencies when extrapolating beyond the training data range. Thus, we will use X_gtext for visualization purposes, but use X_test to
compute uncertainty and calibration metrics because we want to analyse how well the method has learned the noisy data distribution.
[12]:
qr_preds = qr_model.predict_step(X_gtext)
fig = plot_predictions_regression(
X_train,
Y_train,
X_gtext,
Y_gtext,
qr_preds["pred"],
pred_quantiles=np.stack(
[qr_preds["lower_quant"], qr_preds["pred"].squeeze(), qr_preds["upper_quant"]],
axis=-1,
),
aleatoric=qr_preds["aleatoric_uct"],
title="Quantile Regression",
)
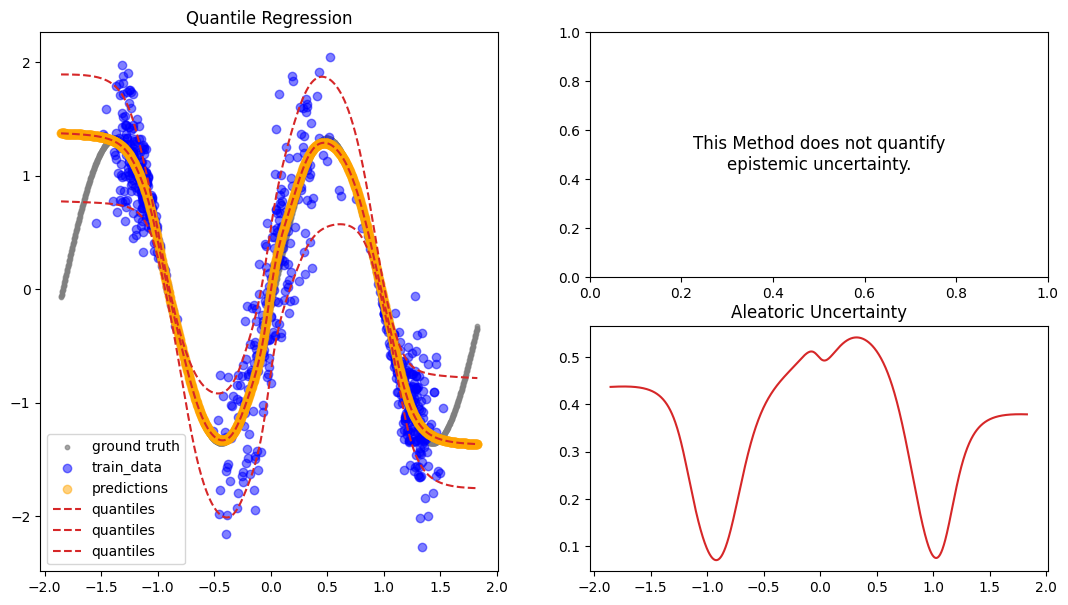
[13]:
qr_preds = qr_model.predict_step(X_test)
fig = plot_calibration_uq_toolbox(
qr_preds["pred"].cpu().numpy(),
qr_preds["pred_uct"].numpy(),
Y_test.cpu().numpy(),
X_test.cpu().numpy(),
)
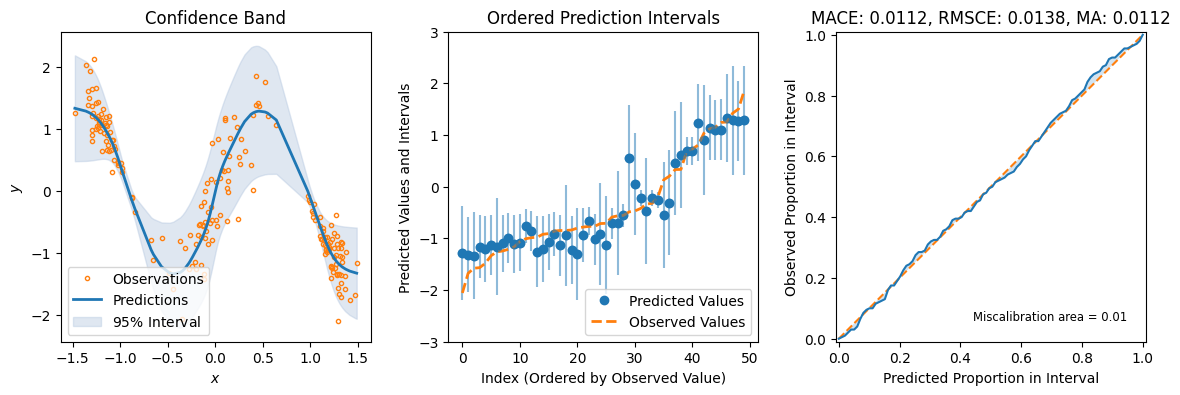
Conformal Prediction#
As a calibration procedure we will apply Conformal Prediction now. The method is implemented in a LightningModule that will compute the \(\hat{q}\) value to adjust the quantile bands for subsequent predictions. The method allows us to define a theoretically guaranteed coverage error rate, which is defined below.
[14]:
conformal_qr = ConformalQR(qr_model, quantiles=quantiles)
[15]:
def empiricial_coverage(targets, lower_quant, upper_quant):
"""Compute empirical coverage.
Args:
targets: targets
lower_quant: lower quantile
upper_quant: upper quantile
Returns:
empirical coverage
"""
targets = targets.squeeze()
lower_quant = lower_quant.squeeze()
upper_quant = upper_quant.squeeze()
emp_cov_bool = (targets >= lower_quant) & (targets <= upper_quant)
return torch.sum(emp_cov_bool).item() / len(emp_cov_bool)
In the next step we are leveraging existing lightning functionality, by casting the post-hoc fitting procedure to obtain q_hat during a “calibration” procedure. For Conformal Prediction it is crucial to have a separate calibration set apart from any validation set you have for your experiment. The datamodule includes a calibration_dataloader() which we will use for the Conformal QR fitting.
[16]:
trainer = Trainer(
enable_checkpointing=False,
enable_progress_bar=False,
default_root_dir=my_temp_dir,
max_epochs=1,
)
trainer.fit(conformal_qr, train_dataloaders=dm.calib_dataloader())
GPU available: False, used: False
TPU available: False, using: 0 TPU cores
HPU available: False, using: 0 HPUs
/home/docs/checkouts/readthedocs.org/user_builds/lightning-uq-box/envs/stable/lib/python3.12/site-packages/lightning/pytorch/trainer/connectors/logger_connector/logger_connector.py:75: Starting from v1.9.0, `tensorboardX` has been removed as a dependency of the `lightning.pytorch` package, due to potential conflicts with other packages in the ML ecosystem. For this reason, `logger=True` will use `CSVLogger` as the default logger, unless the `tensorboard` or `tensorboardX` packages are found. Please `pip install lightning[extra]` or one of them to enable TensorBoard support by default
/home/docs/checkouts/readthedocs.org/user_builds/lightning-uq-box/envs/stable/lib/python3.12/site-packages/lightning/pytorch/core/optimizer.py:182: `LightningModule.configure_optimizers` returned `None`, this fit will run with no optimizer
| Name | Type | Params | Mode
------------------------------------------------------------
0 | model | QuantileRegression | 5.4 K | train
1 | test_metrics | MetricCollection | 0 | train
------------------------------------------------------------
5.4 K Trainable params
0 Non-trainable params
5.4 K Total params
0.021 Total estimated model params size (MB)
28 Modules in train mode
0 Modules in eval mode
/home/docs/checkouts/readthedocs.org/user_builds/lightning-uq-box/envs/stable/lib/python3.12/site-packages/lightning/pytorch/loops/fit_loop.py:298: The number of training batches (1) is smaller than the logging interval Trainer(log_every_n_steps=50). Set a lower value for log_every_n_steps if you want to see logs for the training epoch.
/home/docs/checkouts/readthedocs.org/user_builds/lightning-uq-box/envs/stable/lib/python3.12/site-packages/lightning/pytorch/loops/optimization/automatic.py:132: `training_step` returned `None`. If this was on purpose, ignore this warning...
`Trainer.fit` stopped: `max_epochs=1` reached.
Now we can make predictions for any new data points we are interested in or get conformalized predictions for the entire test set.
[17]:
trainer.test(conformal_qr, dm)
cqr_preds = conformal_qr.predict_step(X_test)
────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────
Test metric DataLoader 0
────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────
testMAE 0.259928435087204
testR2 0.8733813166618347
testRMSE 0.35677164793014526
────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────
To test the results of the Conformal Procedure, we can compare the empirical coverage before and after. And we can see that indeed after Conformal QR the empirical coverage is at the desired rate of at least 1-alpha.
[18]:
qr_preds = qr_model.predict_step(X_test)
cqr_preds = conformal_qr.predict_step(X_test)
print(
"Empirical Coverage before: ",
empiricial_coverage(Y_test, qr_preds["lower_quant"], qr_preds["upper_quant"]),
)
print(
"Empirical Coverage after: ",
empiricial_coverage(Y_test, cqr_preds["lower_quant"], cqr_preds["upper_quant"]),
)
Empirical Coverage before: 0.79
Empirical Coverage after: 0.95
Evaluate Predictions#
[19]:
cqr_preds = conformal_qr.predict_step(X_gtext)
fig = plot_predictions_regression(
X_train,
Y_train,
X_gtext,
Y_gtext,
cqr_preds["pred"].numpy(),
pred_quantiles=np.stack(
[
cqr_preds["lower_quant"],
cqr_preds["pred"].squeeze(-1),
cqr_preds["upper_quant"],
],
axis=-1,
),
aleatoric=cqr_preds["aleatoric_uct"].numpy(),
title="Conformalized Quantile Regression",
)
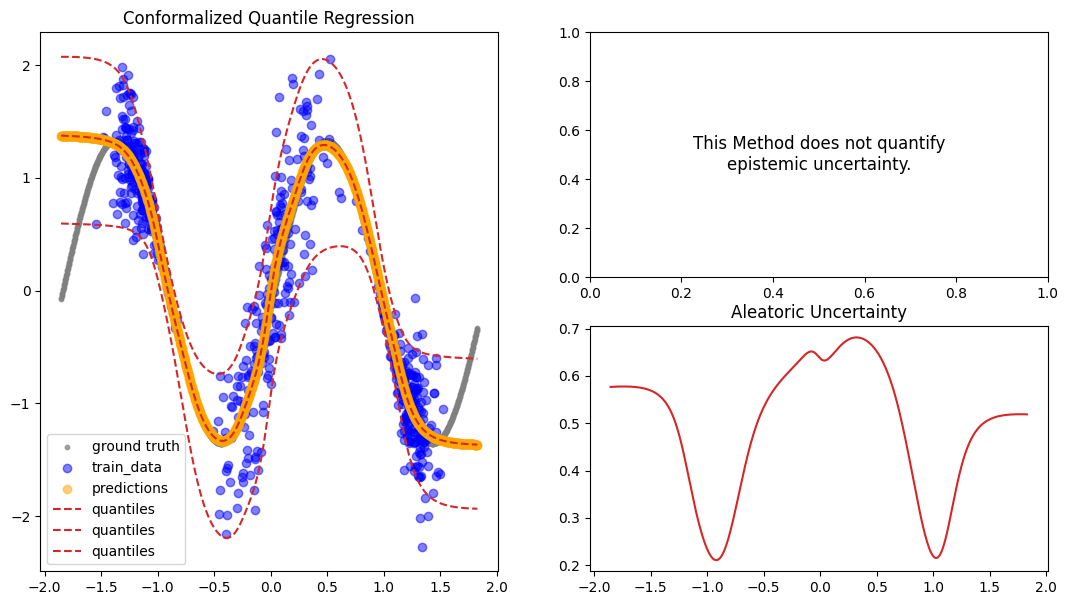
[20]:
cqr_preds = conformal_qr.predict_step(X_test)
fig = plot_calibration_uq_toolbox(
cqr_preds["pred"].cpu().numpy(),
cqr_preds["pred_uct"].numpy(),
Y_test.cpu().numpy(),
X_test.cpu().numpy(),
)
