Variational Bayesian Last Layer (VBLL) with SNGP Regression#
[1]:
%%capture
%pip install git+https://github.com/lightning-uq-box/lightning-uq-box.git
%pip install vbll
[2]:
import os
import tempfile
from functools import partial
import torch
import torch.nn as nn
from lightning import Trainer
from lightning.pytorch import seed_everything
from lightning.pytorch.loggers import CSVLogger
from lightning_uq_box.datamodules import ToyHeteroscedasticDatamodule
from lightning_uq_box.models.fc_resnet import FCResNet
from lightning_uq_box.uq_methods import VBLLRegression
from lightning_uq_box.uq_methods.sngp import RandomFourierFeatures
from lightning_uq_box.uq_methods.spectral_normalized_layers import (
collect_input_sizes,
spectral_normalize_model_layers,
)
from lightning_uq_box.viz_utils import (
plot_predictions_regression,
plot_toy_regression_data,
plot_training_metrics,
)
%load_ext autoreload
%autoreload 2
INFO:root:Asdfghjkl backend not available since the old asdfghjkl dependency is not installed. If you want to use it, run: pip install git+https://git@github.com/wiseodd/asdl@asdfghjkl
[3]:
# temporary directory for saving
my_temp_dir = tempfile.mkdtemp()
seed_everything(42)
Seed set to 42
[3]:
42
Datamodule#
[4]:
# datamodule = ToyDUE(batch_size=32, n_samples=128, normalize=True)
dm = ToyHeteroscedasticDatamodule(batch_size=64)
X_train, Y_train, train_loader, X_test, Y_test, test_loader, X_gtext, Y_gtext = (
dm.X_train,
dm.Y_train,
dm.train_dataloader(),
dm.X_test,
dm.Y_test,
dm.test_dataloader(),
dm.X_gtext,
dm.Y_gtext,
)
[5]:
fig = plot_toy_regression_data(X_train, Y_train, X_test, Y_test)

Model#
[6]:
# todo should be spectral normalized
feature_extractor = FCResNet(
input_dim=1,
features=64,
depth=4,
num_outputs=64,
dropout_rate=0.0,
activation="elu",
)
input_dims = collect_input_sizes(feature_extractor, 1)
feature_extractor = spectral_normalize_model_layers(
feature_extractor, input_dimensions=input_dims, n_power_iterations=1
)
# todo be able to get
rff_features = RandomFourierFeatures(in_dim=64, num_random_features=128)
model = nn.Sequential(feature_extractor, rff_features)
[7]:
vbll_model = VBLLRegression(
model=model,
replace_ll=False, # instead append the VBLL layer
regularization_weight=(1 / X_train.shape[0]) * 2,
optimizer=partial(torch.optim.Adam, lr=4e-3),
num_targets=1,
prior_scale=1.0,
wishart_scale=0.1,
)
Trainer#
[8]:
logger = CSVLogger(my_temp_dir)
trainer = Trainer(
max_epochs=400, # number of epochs we want to train
logger=logger, # log training metrics for later evaluation
log_every_n_steps=1,
enable_checkpointing=False,
enable_progress_bar=True,
default_root_dir=my_temp_dir,
gradient_clip_val=1.0,
)
GPU available: False, used: False
TPU available: False, using: 0 TPU cores
HPU available: False, using: 0 HPUs
[9]:
trainer.fit(vbll_model, dm)
| Name | Type | Params | Mode
-----------------------------------------------------------
0 | model | Sequential | 37.6 K | train
1 | train_metrics | MetricCollection | 0 | train
2 | val_metrics | MetricCollection | 0 | train
3 | test_metrics | MetricCollection | 0 | train
-----------------------------------------------------------
37.6 K Trainable params
1 Non-trainable params
37.6 K Total params
0.150 Total estimated model params size (MB)
25 Modules in train mode
0 Modules in eval mode
`Trainer.fit` stopped: `max_epochs=400` reached.
[10]:
fig = plot_training_metrics(
os.path.join(my_temp_dir, "lightning_logs"), ["train_loss", "trainRMSE"]
)

Evaluate Predictions#
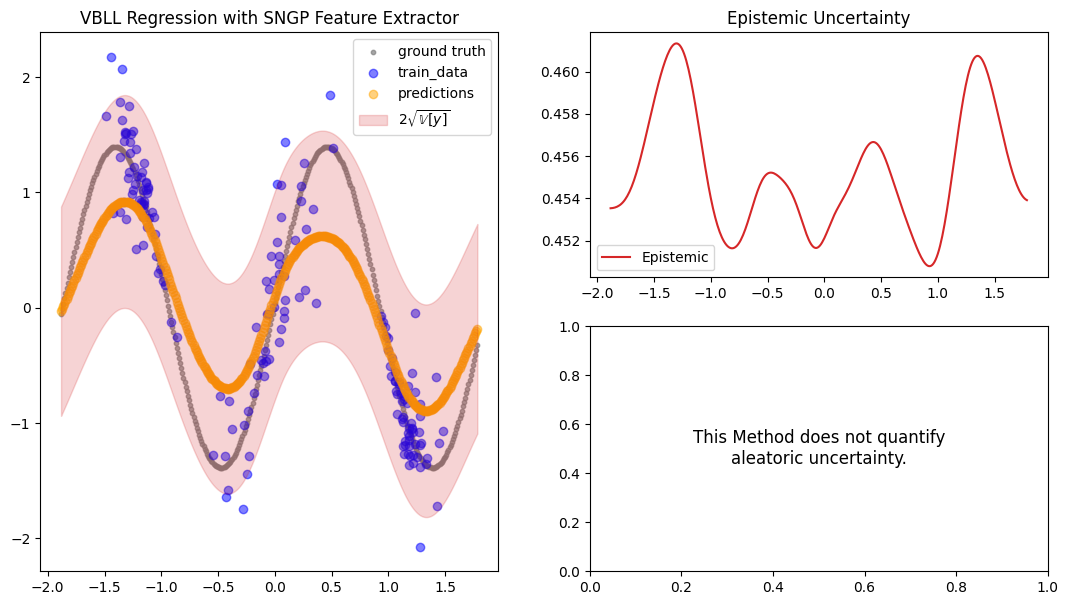
The constructed Data Module contains two possible test variable. X_test are IID samples from the same noise distribution as the training data, while X_gtext (“X ground truth extended”) are dense inputs from the underlying “ground truth” function without any noise that also extends the input range to either side, so we can visualize the method’s UQ tendencies when extrapolating beyond the training data range. Thus, we will use X_gtext for visualization purposes, but use X_test to
compute uncertainty and calibration metrics because we want to analyse how well the method has learned the noisy data distribution.
[11]:
preds = vbll_model.predict_step(X_gtext)
fig = plot_predictions_regression(
X_train,
Y_train,
X_gtext,
Y_gtext,
preds["pred"],
preds["pred_uct"].squeeze(-1),
epistemic=preds["pred_uct"].squeeze(-1),
title="VBLL Regression with SNGP Feature Extractor",
show_bands=False,
)
INFO:matplotlib.mathtext:Substituting symbol V from STIXNonUnicode
INFO:matplotlib.mathtext:Substituting symbol V from STIXNonUnicode
[ ]: